리눅스 메모리 관리
이번 포스팅은 메모리 관리에 관한 동영상 시청 후 정리입니다.
이번 동영상은 꼭 한 번 보시길 추천드립니다. 제가 좋아하는 "왜"필요한지에 대한 설명들이 상세하게 되있습니다.
그리고 내용들이 계속 이어져 있어서 이해하기 훨씬 쉬웠습니다.
📝 메모리란 ?
CPU를 돕기위한 명령어와 데이터를 가지고 있는 주소 덩어리입니다.
프로세스 및 운영체제들이 적재되어 CPU를 점유하여 진행하기위해 대기 중인 저장소입니다.
CPU는 0,1만 읽을 수 있습니다. 그래서 메모리와 CPU중간에는 Compiler가 존재합니다.
Compiler는 아래와 같이 다양한 데이터를 주소 값으로 변경시켜줍니다.

🗯️ 메모리가 관리되는 방법
프로세스 A와 B가 있다고 가정합시다. 그런데 둘의 Logical Address가 겹치는 경우가 대부분입니다.
그럼 어떻게 A와 B를 구별할 수 있을까요? 바로 Physical Address를 더해줍니다.
CPU는 내용만 읽으면 되고 어떤 프로세스인지는 알 필요가 없습니다.
그래서 CPU 진행이 끝난 프로세스를 해석할 수 있는 것이 필요한데 이것이 MMU(Memory Management Unit)입니다.

MMU는 Base register(시작 주소) + CPU가 알고있는 주소를 더해 물리주소를 만들어 줍니다.
그리고 이것을 Limit register(마지막 주소)로 검증합니다.
올바르지 않으면 운영체제에게 프로세스를 종료할 수 있는 권한을 부여합니다.
이렇게 CPU와 메모리간의 프로세스 진행이 이루어집니다.
그럼 메모리에 어떻게 운영체제나 프로세스들을 적재하고 사용할까요?
처음에는 프로세스를 뺐다가 다시 넣고하는 방식을 사용했습니다.
그러나 프로세스의 크기가 다르다보니 중간중간 빈 공간들이 많이 발생하였습니다.
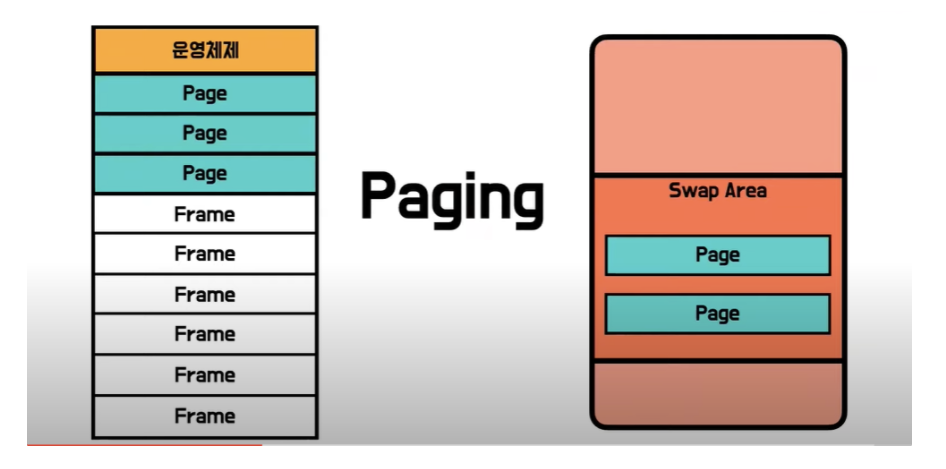
그래서 더 효율적으로 메모리를 사용하기 위해서나온 기법이 Paging기법입니다.
메모리를 똑같은 크기로 자릅니다. 그리고 프로세스도 똑같은 크기로 자릅니다.
이것을 각각 Frame(메모리), Page(프로세스)라고합니다.
그리고 Page들을 사용 할 경우 불필요한 것은 하드 디스크 공간인 Swapping Area에 적재해놓습니다.
그러나 이러한 Pageing기법에도 문제가 발생합니다.
페이지를 나눠서 메모리에 올리다보니 순서가 뒤죽박죽입니다. 그래서 Page Table로 관리하기로 했습니다.
그러나 이 Page Table 상당한 메모리를 차지하기 시작합니다.
그래서 각 프로세스의 공통 부분인 Shared Page를 지정해주게됩니다.
Table이 생기면서 CPU는 메모리에 접근 할 경우 2번 접근해야하는 속도 문제가 발생합니다.
이것을 해결하기 위해서 나온것이 TLB(Translation Look-aside Buffers)입니다.
일종의 캐시 메모리라고 생각하시면 됩니다.
그래서 CPU가 원하는 주소가 TLB에 존재할 경우 바로 데이터를 넘겨주고 없으면 전과 같이 2번 수행하게 됩니다.
어떻게 보면 비효율적이라 할 수 있지만 대부분의 프로세스들은 반복적으로 접근하기 때문에 효율적이게 됩니다.
🗯️ 운영체제의 역할
운영체제는 두 가지의 역할을 하게됩니다.
첫 번째로 가상 메모리로 사용자 프로세스 속이기입니다.
두 번째로는 하드 디스크와 메모리간의 I/O을 관리합니다.
가상 메모리는 물리적 메모리 + 하드 디스크의 Swapping Area공간을 합친 부분을 말합니다.
앞에서는 CPU와 메모리 간의 동작을 살펴봤습니다. 이제는 메모리와 하드 디스크간의 동작을 살펴보겠습니다.
흐름은
"Page Fault → Page Replacement → Thrashing → Working set 및Page Fault Frequency알고리즘이용"입니다.
하나씩 살펴보겠습니다.
1️⃣ Page Fault
CPU가 프로세스를 진행하던 중 TLB와 메모리에 없는 페이지를 요구하는 상황입니다.
그렇다면 프로세스 일시 중단 후 운영체제가 CPU를 점유하게 됩니다.
운영체제는 하드 디스크에서 Page를 가져와 메모리에 등록 후 TLB에 등록합니다.
그러나 큰 문제점은 굉장히 많은 시간이 걸리게 되고 다른 프로세스들이 실행될 수 있습니다.
그렇다면 대기 상태에 들어가 프로세스가 느리게 진행되는데 이러한 상황을 Page Fault라고합니다.
2️⃣ Page Replacement
Page를 계속 메모리에 적재하게되면 언젠가는 메모리가 꽉 차는 경우가 발생합니다.
이 때 LRU알고리즘을 사용해 오래된 Page를 삭제해주면 됩니다.
하지만 LRU를 사용하려면 정확한 사용 Page사용 시점을 알고 있어야합니다.
그러나 Page Fault로 인하여 프로세스가 밀릴 수도 있고하는 상황이 있을 수 있습니다.
그래서 Reference bit를 사용한 "Clock Algoritm"을 이용하게 됩니다.
이 알고리즘은 가장 오래된 것은 못 찾지만 최근 사용된 참조는 피할 수 있다는 장점을 가지고 있습니다.
그리고 메모리에서 Page를 없앨 경우 주의해야하는 사항이 있습니다.
Swapping Area에도 변경된 점을 같이 업데이트 해줘야합니다.(Dirty Bit사용)
3️⃣ Thrashing
계속해서 다양한 Page가 올라오면서 자원을 최대한 활용하는 상황인데 갑자기 CPU가동률이 쭉 떨어지게 됩니다.
왜 그럴까요? 바로 앞에서 말한 Page Replacement입니다.
계속된 Page교체로 인하여 프로세스는 중단이 되고 운영체제는 쉬고 있는 CPU를 보고 계속 프로세스를 올립니다.
이러한 현상을 Thrashing이라고 합니다. 이러한 현상이 계속되면 프로세스는 다운됩니다.
이러한 문제들이 많이 생기고 있고 나날이 가면서 더 좋은 방법들을 적용시켜나가고 있습니다.
그래서 우리는 항상 CPU의 가동률을 확인해줘야합니다. 겉으로는 좋아보이지만 한 순간에 떨어질 수 있기 때문입니다.
최악의 상황은 실제 서비스의 서버가 다운되는 상황이 발생 할 수 있습니다.
이번 포스팅으로 많은 것을 배웠습니다. 내일은 어떤 CS지식을 공부할지 설레네요.