[23.12.18] 로컬 데이터 레이크 만들기
데이터 레이크는 정형 및 비정형을 변환없이 저장 할 수 있는 저장소이다.
클라우드 회사들은 데이터 레이크 인프라 및 툴을 제공한다.
예를 들면 AWS에서 제공하는 Athena는 S3 Storage + Presto SQL 기반으로 동작한다.
우리는 인프라 및 툴을 직접 구축하는 간단한 실습을 해 볼 예정이다.
실습 3개의 구성 요소
1. Storage Layer: MinIO(S3 대체)
S3를 대체할 수 있는 MinIo를 이용하여 스토리지 레이어를 구성한다. 이것은 온프레미스 환경의 데이터레이크를 구축하게 도와준다.
물론 MinIO말고 다른 오픈소스들도 활용 할 수 있다.
2. Mapping File and Directory to Table: Hive Metastore
Mariadb를 사용한다.
Hive Connector는 우리가 S3 스토리지에 쿼리를 할 수 있도록 지원한다.
그러기 위해서는 S3에 저장된 파일 및 디렉토리를 Table로 매핑하여 관리해야한다. 그것을 위해 HMS를 사용한다.
컬럼, 파일 위치, 파일 포맷 다양한 메타데이터를 관리한다.
3. Query Engine: Trino(Presto SQL)
트리노는 MPP(Massive Parallel Processing) 데이터베이스와 유사한 아키텍처를 활용하는 분산 시스템이다.
다른 분산 시스템과 같이 마스터 + 여러개의 워커노드가 존재한다.
실습
아래의 github clone 받아서 진행
https://github.com/hnawaz007/pythondataanalysis/tree/main/data-lake
1. 도커 컴포즈를 이용한 컨테이너 띄우기(docker compose up)
* trino : trino351
* mariadb: 10.5.8
* hive-metastore: latest
* minIo: RELEASE.2021-01-08T21-18-21Z
version: '3.7'
services:
trino:
hostname: trino
image: 'trinodb/trino:351'
ports:
- '8085:8080'
volumes:
- ./etc:/usr/lib/trino/etc:ro
networks:
- trino-network
mariadb:
hostname: mariadb
image: mariadb:10.5.8
ports:
- 3306:3306
environment:
MYSQL_ROOT_PASSWORD: admin
MYSQL_USER: admin
MYSQL_PASSWORD: admin
MYSQL_DATABASE: metastore_db
networks:
- trino-network
hive-metastore:
hostname: hive-metastore
image: 'bitsondatadev/hive-metastore:latest'
ports:
- '9083:9083' # Metastore Thrift
volumes:
- ./conf/metastore-site.xml:/opt/apache-hive-metastore-3.0.0-bin/conf/metastore-site.xml:ro
environment:
METASTORE_DB_HOSTNAME: mariadb
depends_on:
- mariadb
networks:
- trino-network
minio:
hostname: minio
image: 'minio/minio:RELEASE.2021-01-08T21-18-21Z'
container_name: minio
ports:
- '9095:9000'
volumes:
- minio-data:/data
environment:
MINIO_ACCESS_KEY: minio_access_key
MINIO_SECRET_KEY: minio_secret_key
command: server /data
networks:
- trino-network
volumes:
minio-data:
driver: local
networks:
trino-network:
driver: bridge
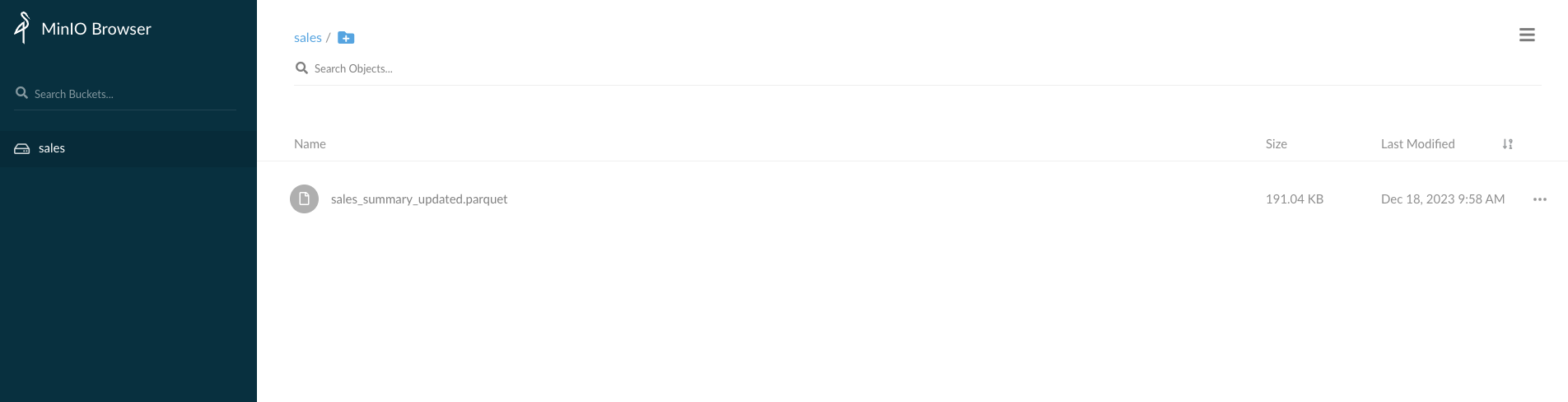
2. S3 Bukect 확인
localhost:9095 접근하여 access_key 및 private_key 입력.(docker파일 참조)
오른쪽 하단의 "+" 버튼을 누르고 "sales" 버킷을 생성.
"sales_summary_updated.parquet" 파일 업로드.
3. 트리노 엔진을 이용하여 SQL 실행
S3 File을 HMS를 사용하여 테이블로 매핑하고 SQL을 실행시켜보자.
Datagrip 또는 DBeaver를 사용하여 SQL을 8085 포트로 연결시켜보자. Driver를 다운로드하자.
아래의 코드로 S3와 HMS 메타데이터를 매핑시켜보자.
CREATE SCHEMA IF NOT EXISTS minio.sales
WITH (location = 's3a://sales/');
External Table까지 생성해보자.
CREATE TABLE IF NOT EXISTS minio.sales.sales_parquet (
productcategoryname VARCHAR,
productsubcategoryname VARCHAR,
productname VARCHAR,
country VARCHAR,
salesamount DOUBLE,
orderdate timestamp
)
WITH (
external_location = 's3a://sales/',
format = 'PARQUET'
);
쿼리를 날려보자.
SELECT
productcategoryname, sum(salesamount) as sales
FROM minio.sales.sales_parquet
where country = 'United States'
group by productcategoryname
참고 : https://aws.plainenglish.io/build-your-own-data-lake-on-your-infrastructure-c5015658b237