Data Engineering
Spark + Iceberg - 3(Hidden Partitioning)
HOONY_612
2024. 1. 17. 20:25
반응형
소개
아이스버그의 히든 파티셔닝 기능을 알아보자.
기존 하이브 테이블 파티셔닝은 쿼리 속도를 향상시키기 위해서 파티셔닝을 사용한다.
아래 예시처럼 "event_date" 컬럼이 하나가 추가된다.
Insert할 때도 변환이 필요해 불필요한 작업이 늘어난다.
INSERT INTO logs PARTITION (event_date)
SELECT level, message, event_time, format_time(event_time, 'YYYY-MM-dd')
FROM unstructured_log_source
그리고 아래 예시처럼 마지막 event_date를 적어야만 Full Scan을 하지않고 데이터를 가져온다.
SELECT level, count(1) as count FROM logs
WHERE event_time BETWEEN '2018-12-01 10:00:00' AND '2018-12-01 12:00:00'
AND event_date = '2018-12-01'
또 다양한 문제들이 존재한다.
파티션 값을 검증하지 못한다. 소스 Cloumn이 잘못되면 파티션도 영향을 받는다.
쿼리는 파티션에 의존적이고 성능에 영향을 많이받는다.
이러한 문제를 해결해주는 것이 Iceberg Hidden Partitioning이다.
아래 그림은 파티셔닝 해줄 때 사용할 수 있는 Transform 기능이다.

실습
1. CREATE TABLE
create table hidden_logs (
ID BIGINT,
LEVEL STRING,
MESSAGE STRING,
EVENT_TIME TIMESTAMP
) USING ICEBERG
LOCATION 's3a://martinispark/hiddenpartition'
PARTITIONED BY (day(EVENT_TIME))
2. INSERT INTO Data
별도의 Table Column 추가 없이 일별 파티션이 나누어지는 것을 볼 수 있다.
INSERT INTO hidden_logs VALUES
(1,'DEBUG','saveItems',TIMESTAMP '2024-01-17 10:00:00'),
(2,'DEBUG','getItems', TIMESTAMP '2024-01-17 10:00:10'),
(3,'DEBUG','updateItems',TIMESTAMP '2024-01-18 10:00:00')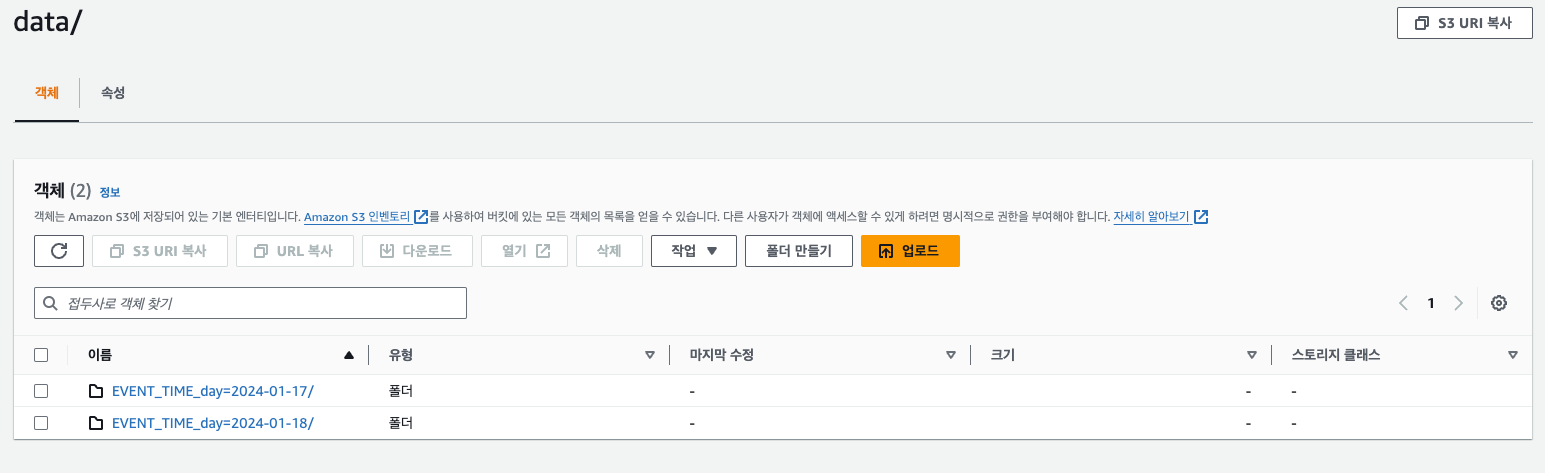
3. ALTER PARTITION
파티션 기준을 월별로 변경해보자.
ALTER TABLE hidden_logs REPLACE PARTITION FIELD day(EVENT_TIME) WITH month(EVENT_TIME)
4. INSERT INTO Data
월별로 변경되는 것을 볼 수 있다.
INSERT INTO hidden_logs VALUES
(4,'DEBUG','saveItems',TIMESTAMP '2025-01-17 10:00:00'),
(5,'DEBUG','getItems', TIMESTAMP '2025-01-18 10:00:10'),
(6,'DEBUG','updateItems',TIMESTAMP '2025-02-18 10:00:00'),
(7,'DEBUG','saveItems',TIMESTAMP '2025-02-19 10:00:00'),
(8,'DEBUG','getItems', TIMESTAMP '2025-03-17 10:00:10'),
(9,'DEBUG','updateItems',TIMESTAMP '2025-03-18 10:00:00')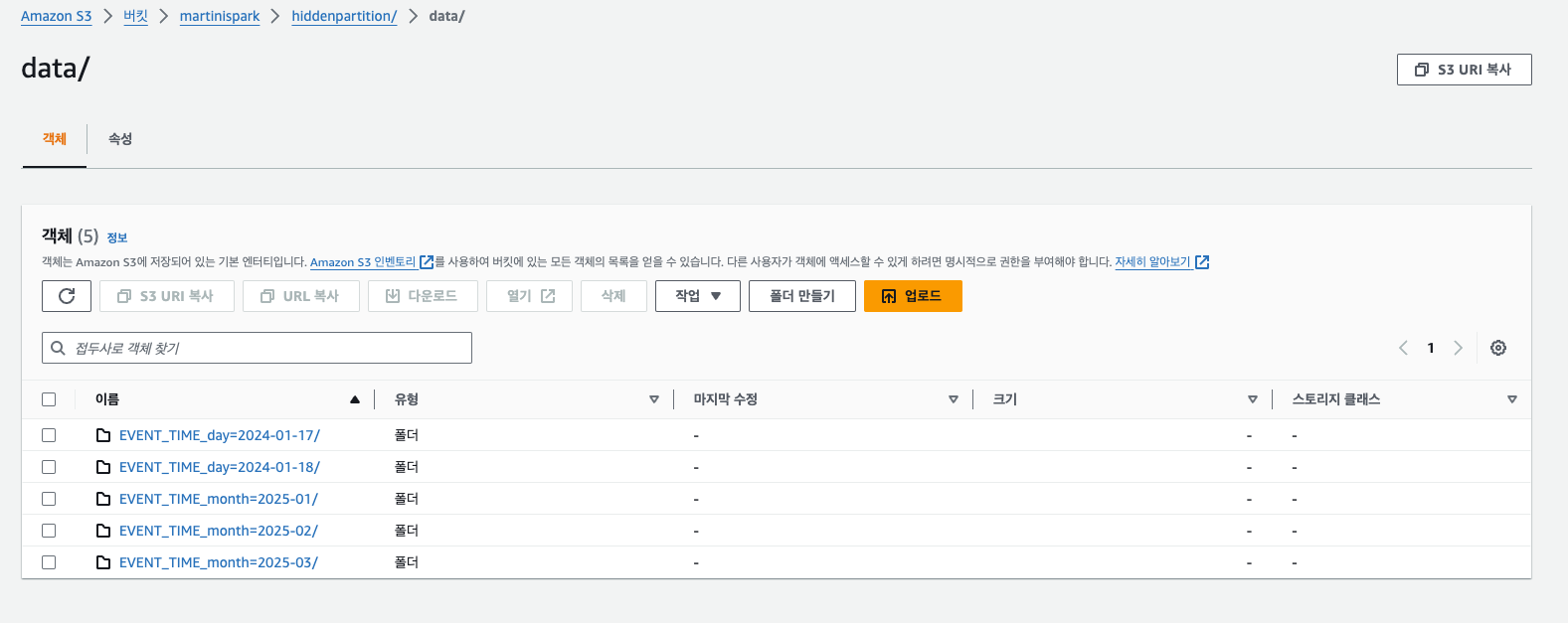
5. SELECT TABLE
조회 쿼리는 파티션이 변경되어도 변하지 않는다. 사용자는 어떻게 파티셔닝이 구성되어 있는지 모른다.
그리고 따로 날짜를 정해줄 필요도 없다.
SELECT * FROM hidden_logs
WHERE EVENT_TIME BETWEEN '2024-12-01 10:00:00' AND '2025-12-01 12:00:00'반응형